Explorando bibliotecas de visualização: Matplotlib, Plotly e Altair
python
visualização
data-science
Autor
João Pedro F. Duarte
Data de Publicação
10/02/2024
Introdução
A visualização de dados é uma habilidade essencial para qualquer cientista de dados ou engenheiro. Neste post, vamos explorar três bibliotecas populares de visualização em Python: Matplotlib, Plotly e Altair.
Dataset de Exemplo
Vamos usar um dataset sintético para demonstrar diferentes tipos de visualizações:
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport plotly.express as pximport plotly.graph_objects as go# Configurar seed para reprodutibilidadenp.random.seed(42)# Criar dataset sintéticon_samples =200data = pd.DataFrame({'x': np.random.randn(n_samples),'y': np.random.randn(n_samples),'categoria': np.random.choice(['A', 'B', 'C', 'D'], n_samples),'valor': np.random.uniform(10, 100, n_samples),'tempo': pd.date_range('2024-01-01', periods=n_samples, freq='D')})# Adicionar correlaçãodata['y'] = data['y'] +0.5* data['x'] + np.random.randn(n_samples) *0.3print(data.head())print(f"\nShape: {data.shape}")
x y categoria valor tempo
0 0.496714 0.219156 C 51.628124 2024-01-01
1 -0.138264 0.103129 C 77.272384 2024-01-02
2 0.647689 1.306160 A 13.301488 2024-01-03
3 1.523030 2.316023 A 32.719325 2024-01-04
4 -0.234153 -1.572623 D 74.201463 2024-01-05
Shape: (200, 5)
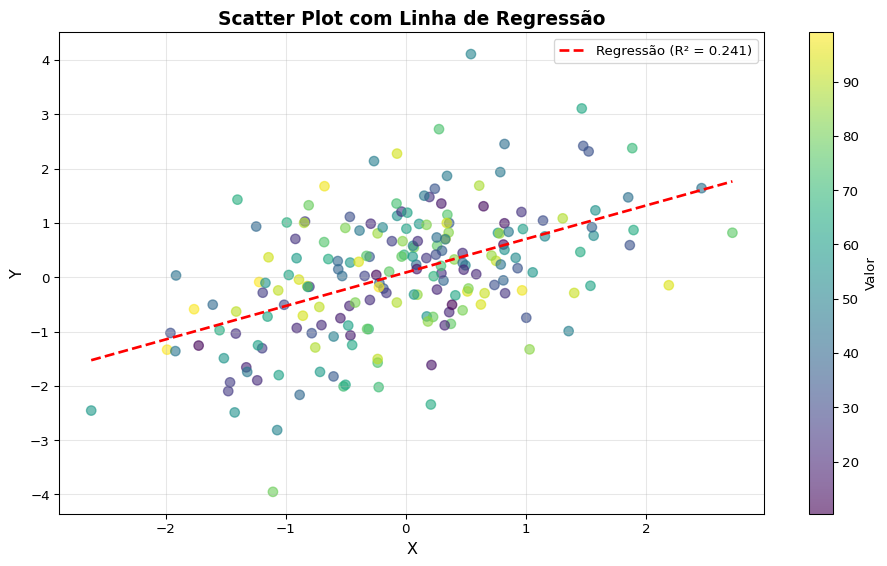
1. Matplotlib: O Clássico
Matplotlib é a biblioteca de visualização mais tradicional do Python. Oferece controle total sobre cada aspecto do gráfico.
# Agregar dados por tempo e categoriats_data = data.groupby(['tempo', 'categoria'])['valor'].mean().reset_index()fig = px.line( ts_data, x='tempo', y='valor', color='categoria', title='Evolução Temporal por Categoria', labels={'tempo': 'Data', 'valor': 'Valor Médio'})fig.update_xaxes( rangeslider_visible=True, rangeselector=dict( buttons=list([dict(count=1, label="1m", step="month", stepmode="backward"),dict(count=3, label="3m", step="month", stepmode="backward"),dict(count=6, label="6m", step="month", stepmode="backward"),dict(step="all", label="Tudo") ]) ))fig.update_layout(height=500)fig.show()
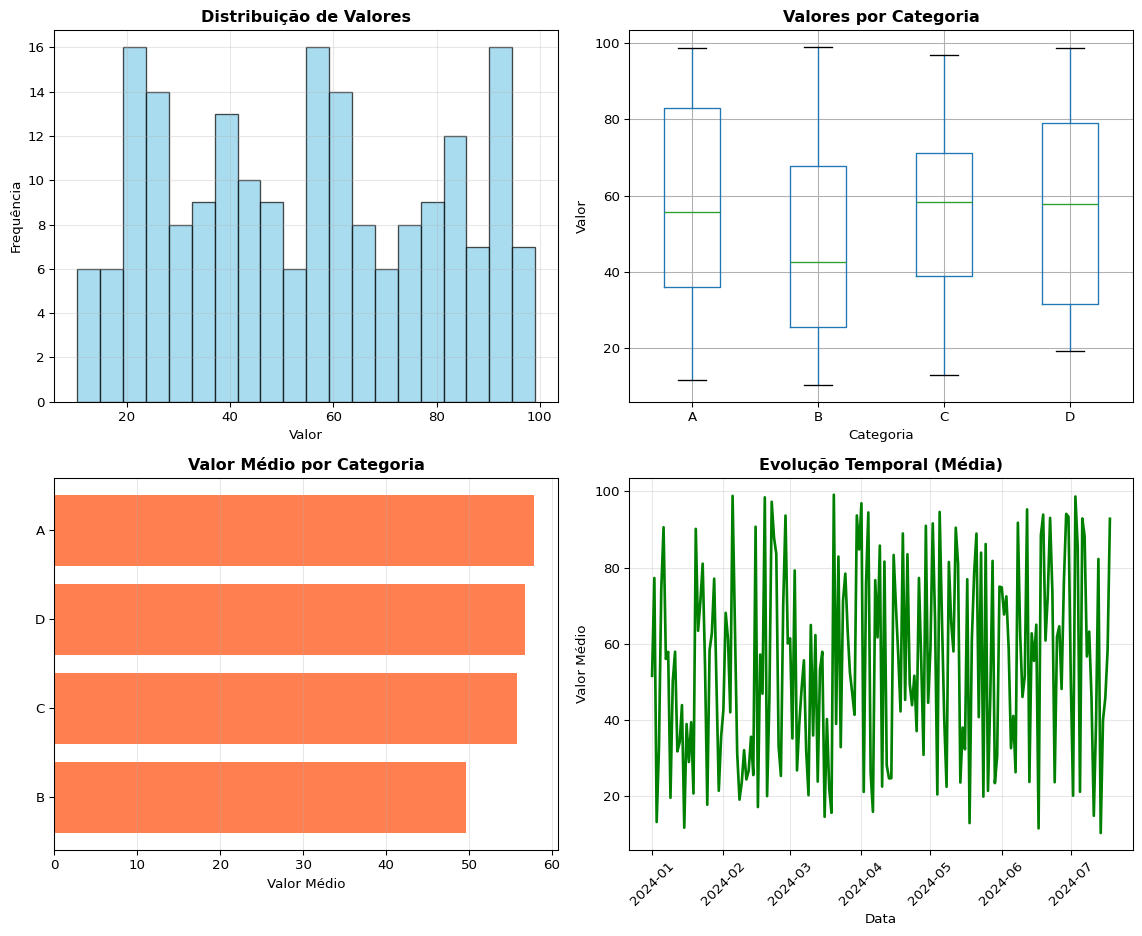
3. Estatísticas Descritivas
print("Estatísticas Descritivas:")print("="*50)print(data[numeric_cols].describe())print("\n\nContagem por Categoria:")print("="*50)print(data['categoria'].value_counts())
Estatísticas Descritivas:
==================================================
x y z valor
count 200.000000 200.000000 200.000000 200.000000
mean -0.040771 0.061824 0.610739 54.768640
std 0.931004 1.168072 1.232384 25.334563
min -2.619745 -3.951252 -1.996559 10.416882
25% -0.705128 -0.659598 -0.175267 32.587442
50% -0.004192 0.120707 0.438314 55.607458
75% 0.500852 0.826598 1.040599 76.988763
max 2.720169 4.107723 6.555791 99.096421
Contagem por Categoria:
==================================================
categoria
B 56
A 54
C 51
D 39
Name: count, dtype: int64